Build production-grade data pipelines
For data teams who want reliable ETL with native DuckDB and Ducklake integrations. No Airflow or Spark clusters to manage.







Trusted by 4,000+ organizations, including 300+ EE customers at scale:

















Everything you need to build and run production-grade data pipelines
Write each step in Python, TypeScript, SQL, Go, Bash or any supported language, connect to your data sources with native DuckDB and Ducklake integrations, and deploy with built-in scheduling, retries and observability.
Steps as code
Write each pipeline step in the language that fits best. Python, TypeScript, SQL, Go, Bash, Rust, PHP and 20+ more. Mix and match freely within a single pipeline.
DAG visualizer
See your entire pipeline as an interactive graph. Inspect inputs and outputs at each node, follow data as it flows between steps, spot bottlenecks at a glance and restart from any step without replaying the full run.
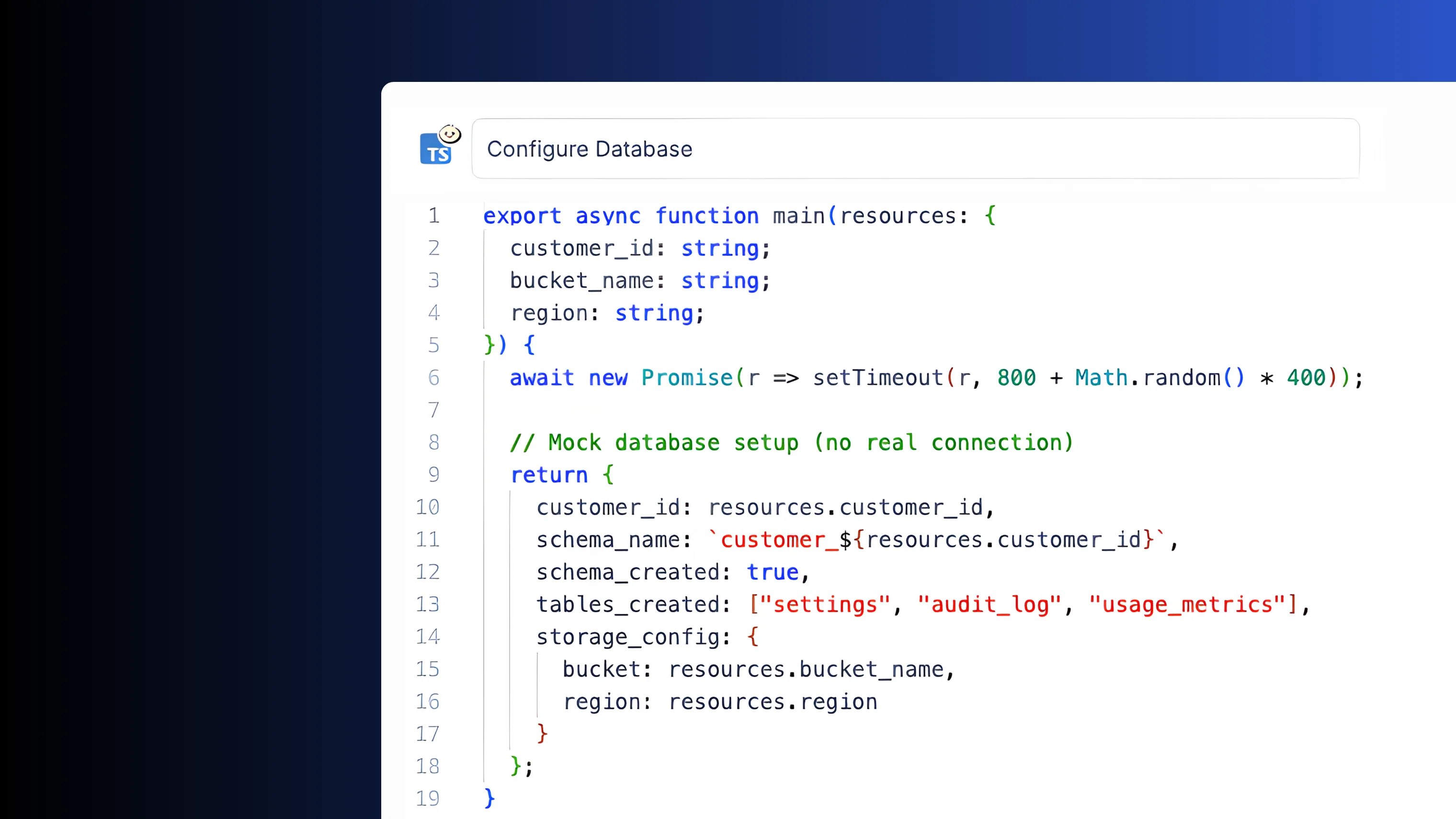
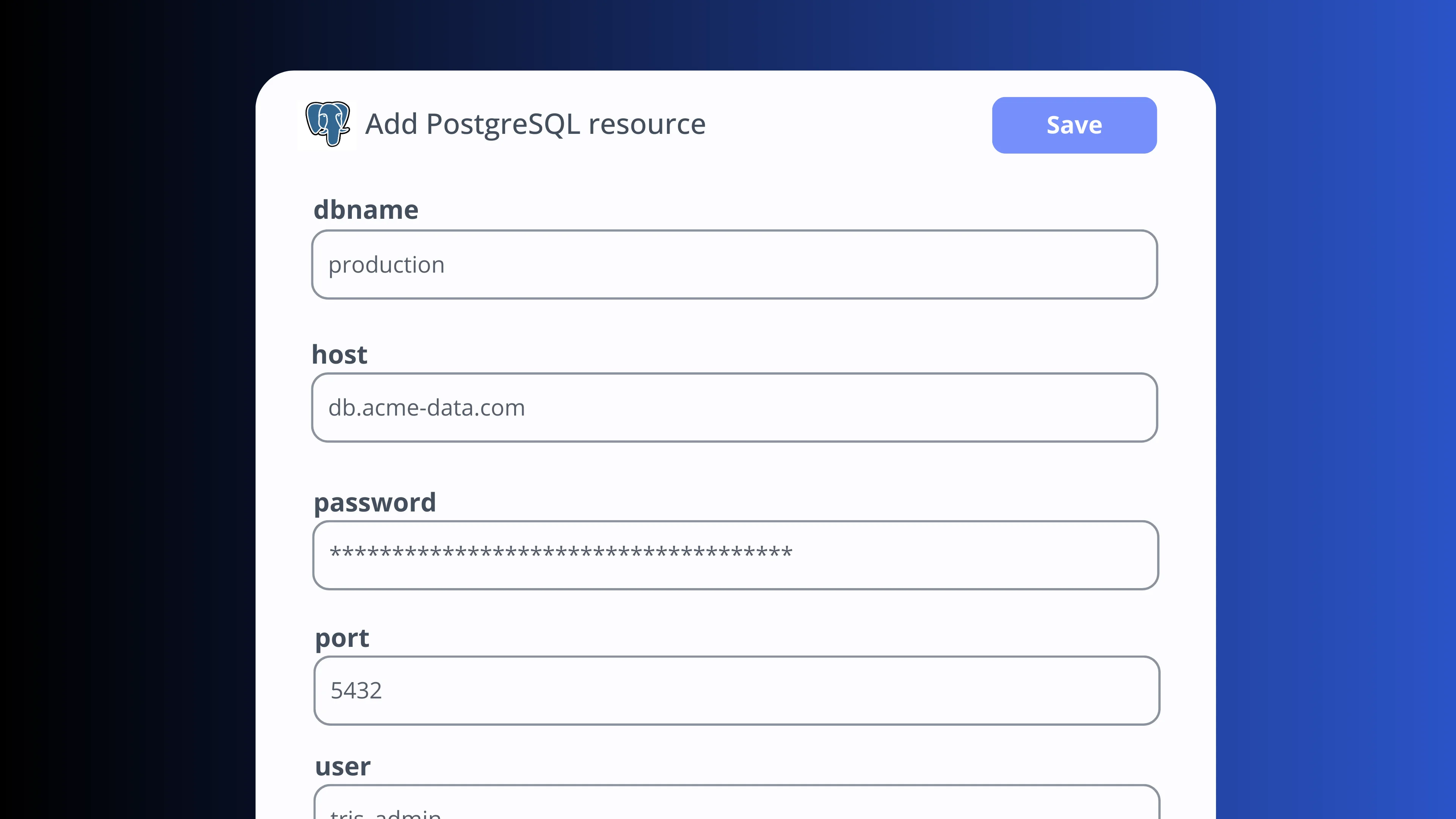
Connect to any service
Connect to databases, APIs and third-party services using typed resources. Credentials are stored centrally and injected at runtime. Share connections across scripts and flows without duplicating secrets.
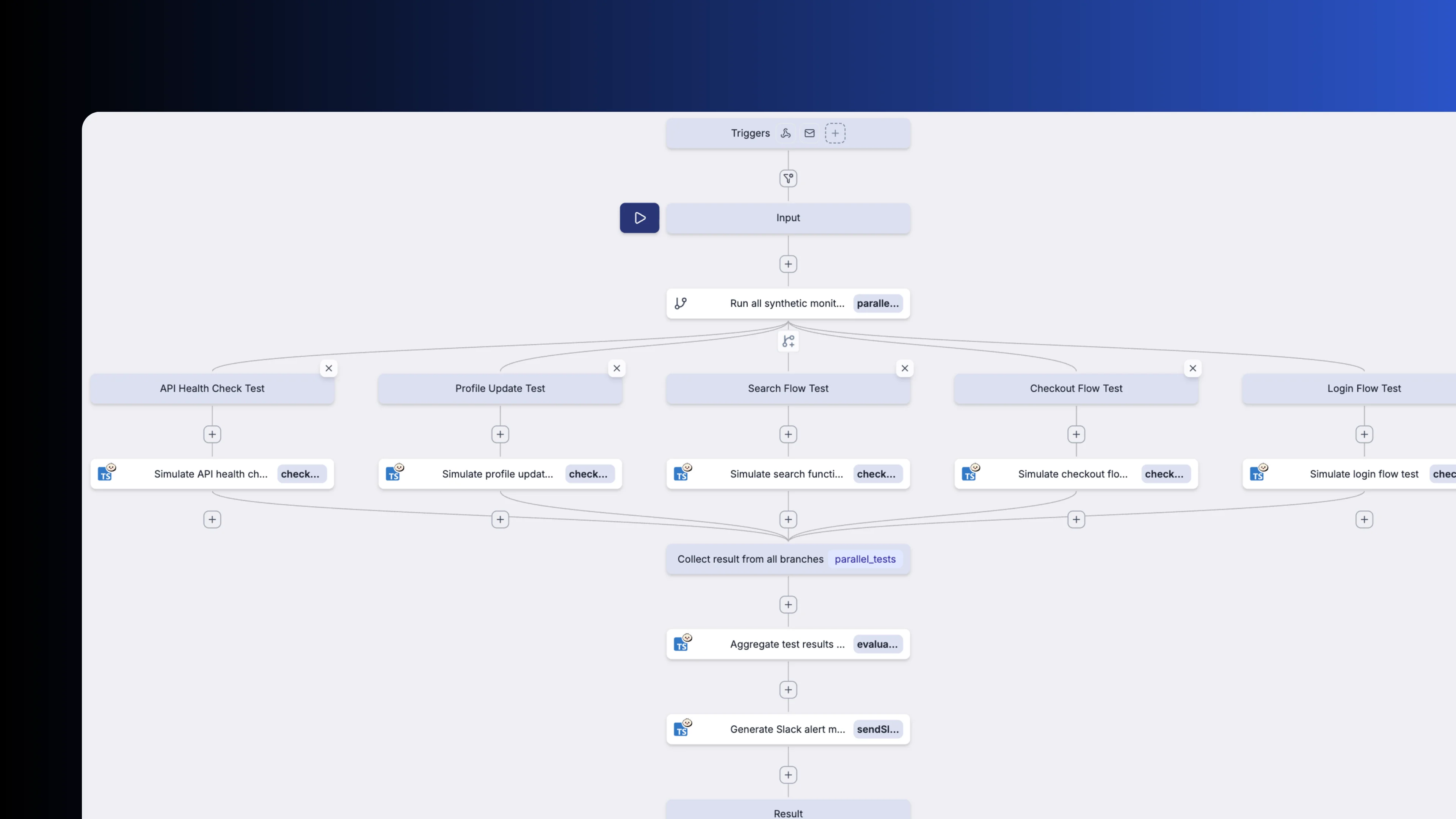
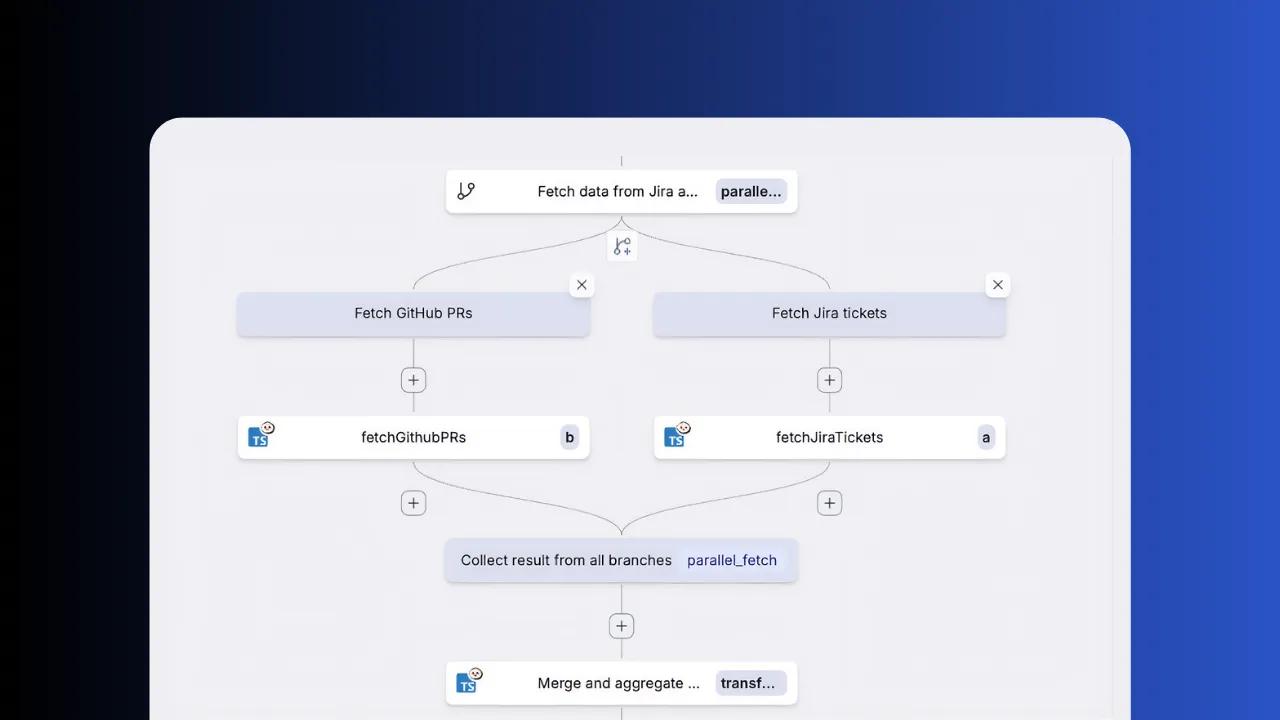
Parallel branches
Fan out extraction steps across independent sources with parallel branches and collect results automatically. Configure for-loops with configurable parallelism to process batches concurrently.
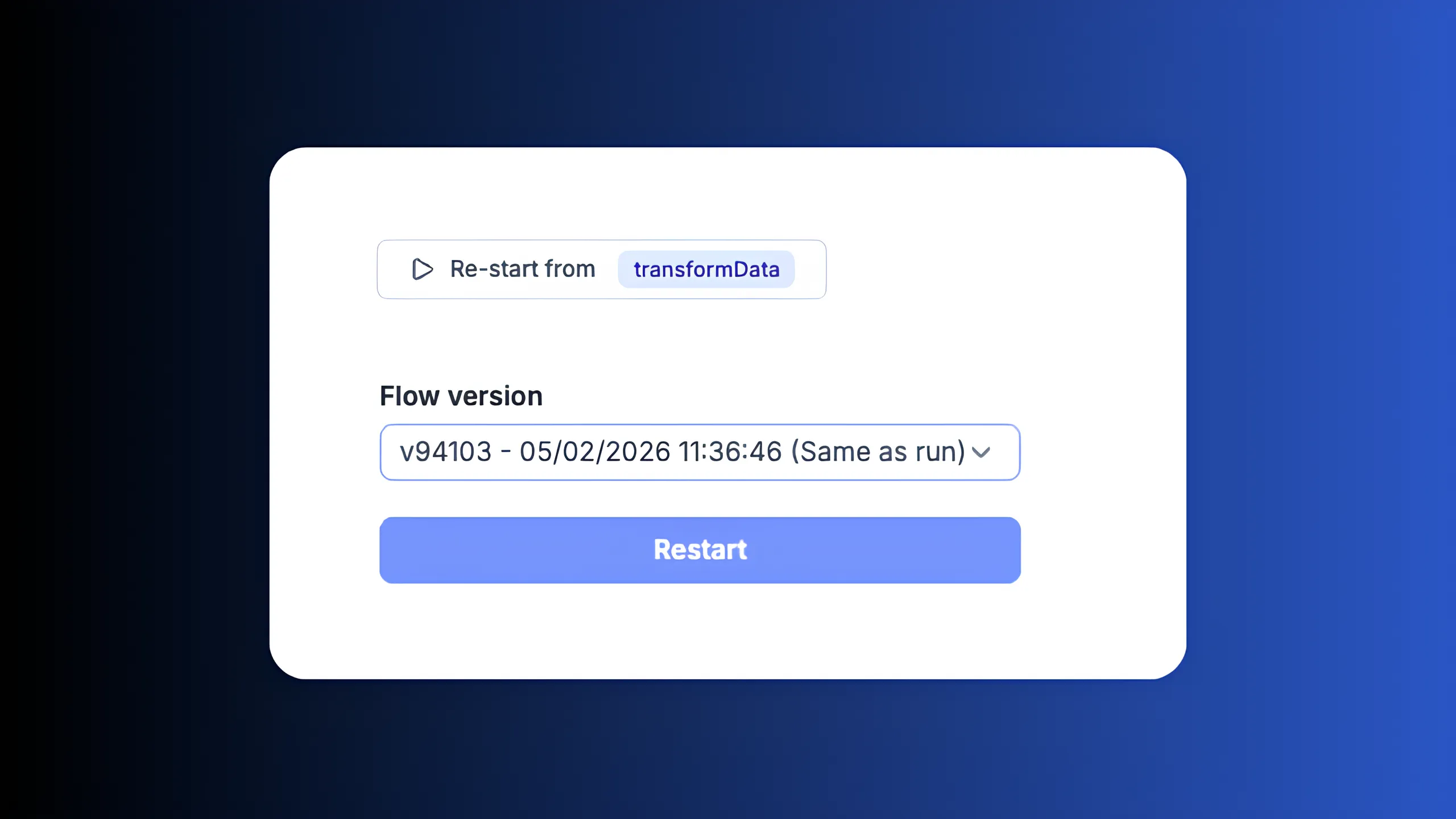
Restart from any step
Fix a bug and re-run from the failing step in the flow editor. No need to replay the entire pipeline or re-extract data from upstream sources.
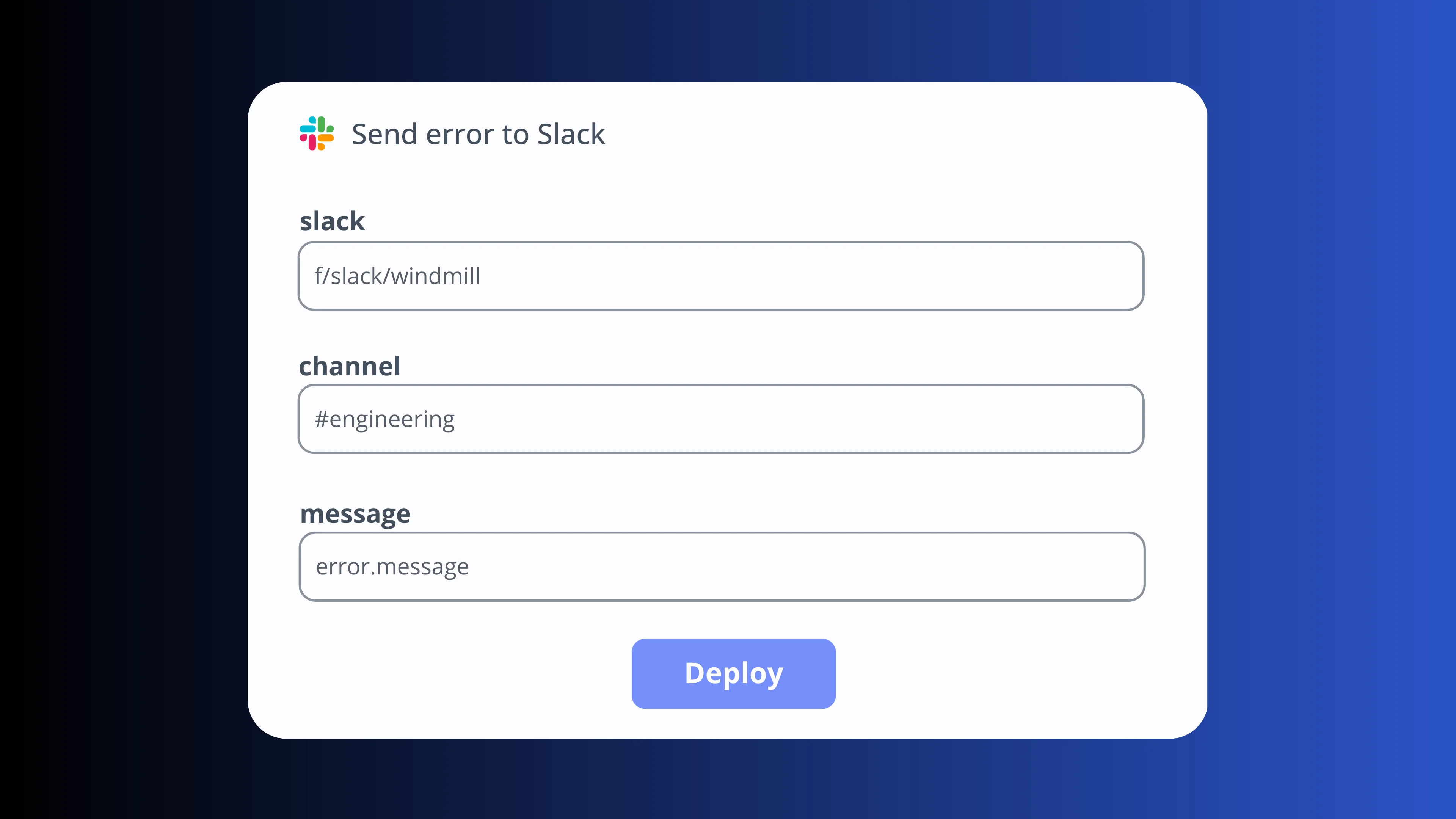
Retries & error handlers
Each step can have its own error handling strategy and configurable retries with exponential backoff. Run a custom script on failure (send a Slack alert, create a ticket), stop the pipeline early or mark non-critical steps to continue on error.
Trigger from anywhere
Start pipelines from cron schedules, webhooks, Postgres CDC, Kafka, SQS, or manually from the UI. Combine multiple trigger types on the same pipeline.

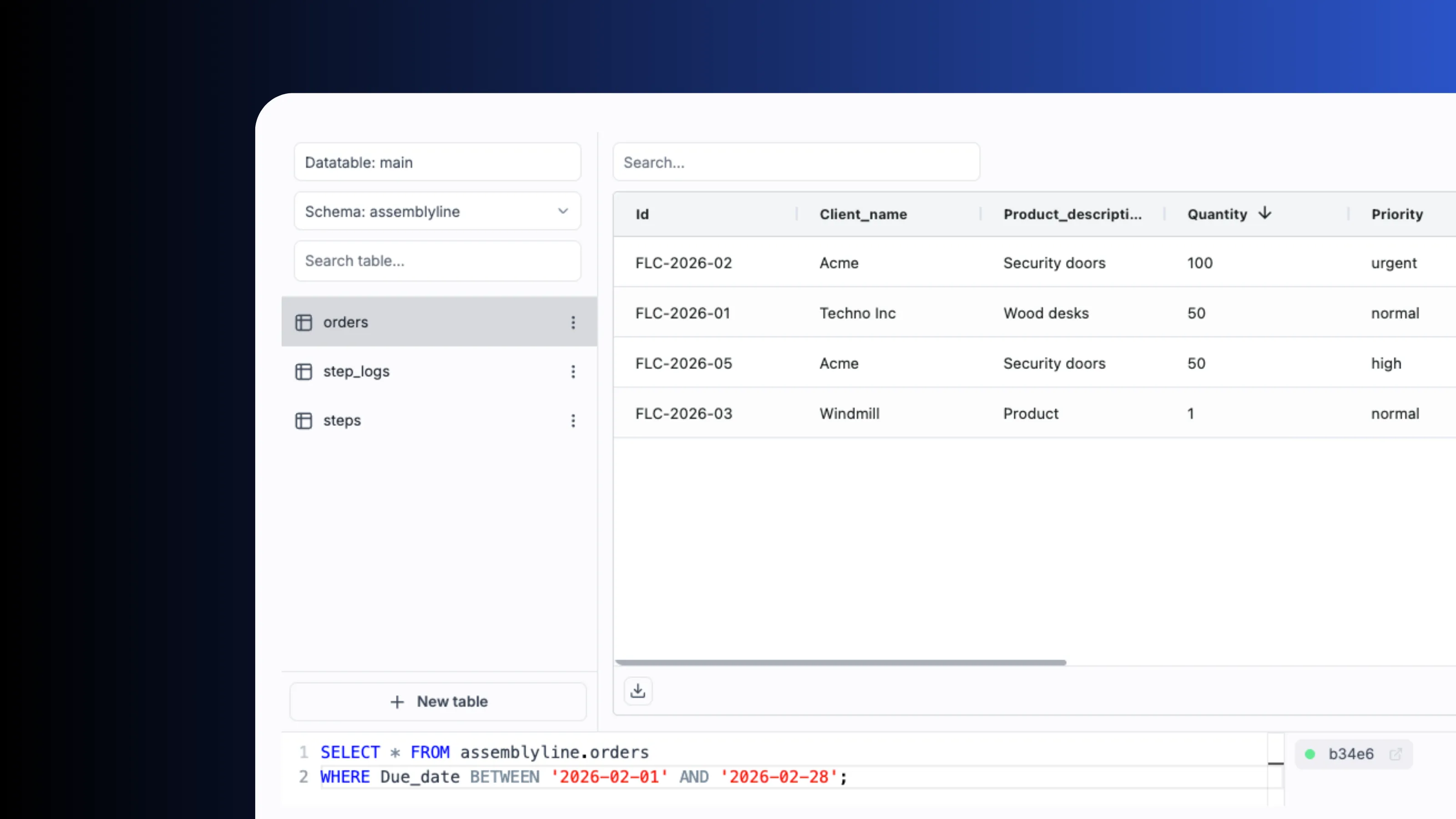
Data tables
Built-in relational storage with zero setup via data tables. Query from Python, TypeScript, SQL or DuckDB. Credentials are managed internally and never exposed.
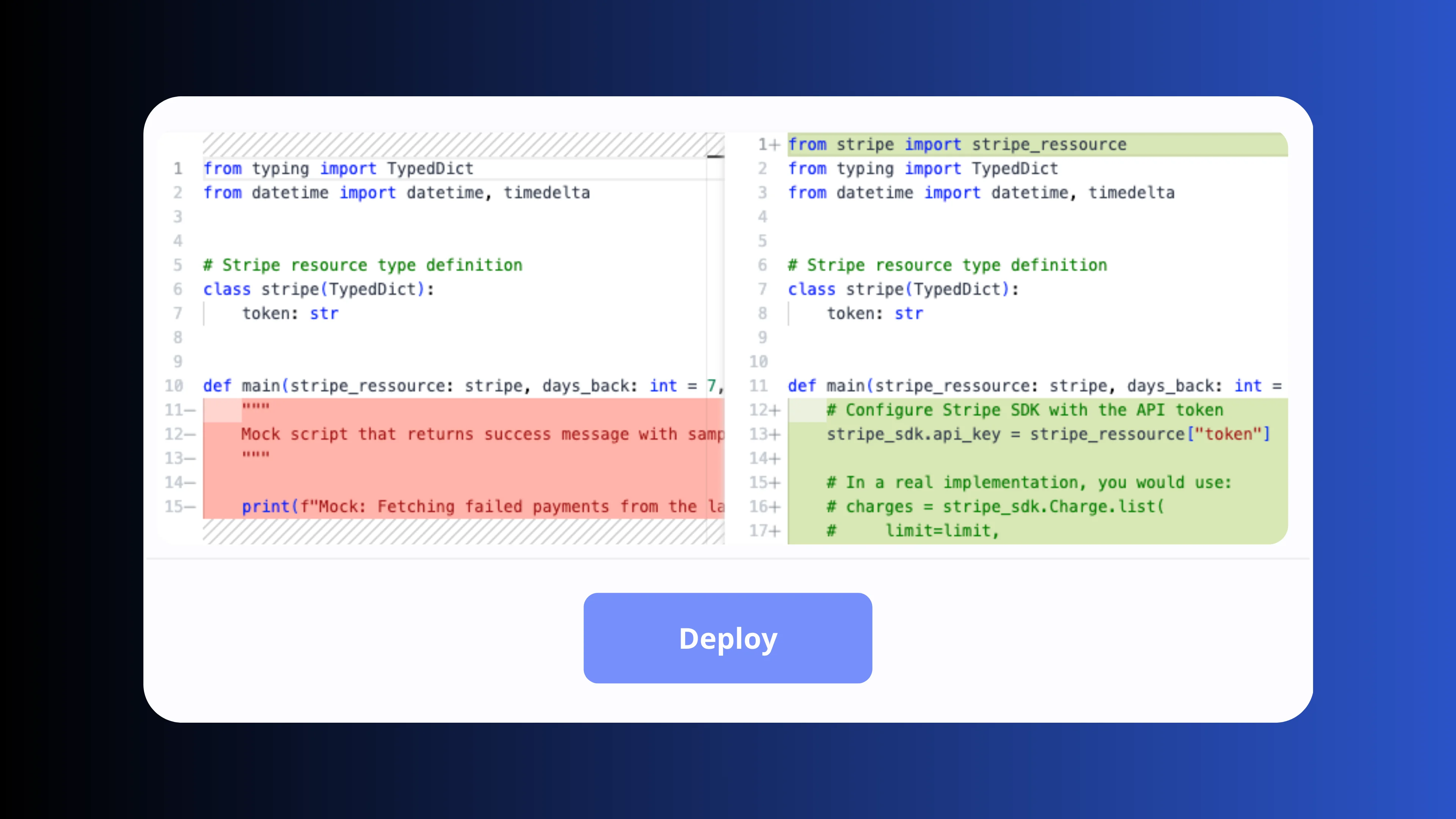
Deploy & version control
Promote pipelines from draft to production in one click with full deployment history and instant rollbacks. Sync your workspace with GitHub or GitLab, use your existing code review workflows and deploy via the UI, the CLI or CI/CD pipelines.
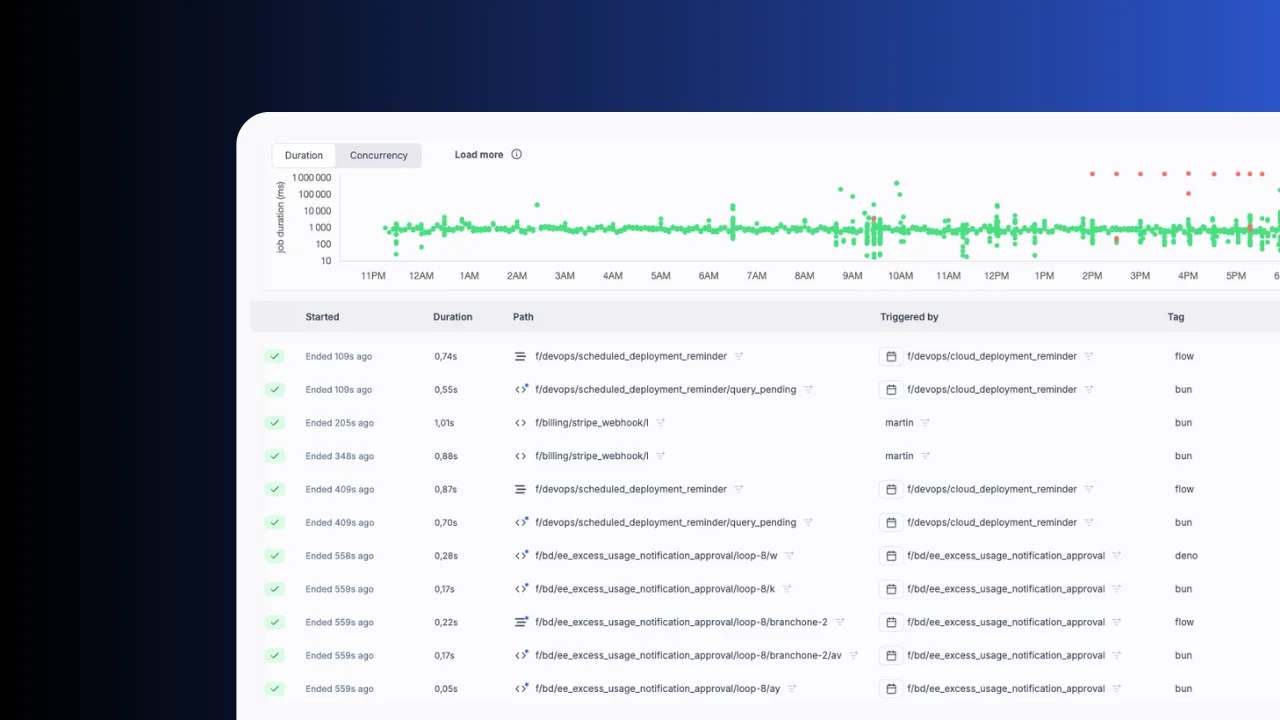
Full observability
Every pipeline run is logged with inputs, outputs, duration and status. Filter by success or failure, inspect logs and re-run with one click. Track resource usage, monitor worker groups and set up alerts for failures.
The native DuckDB and Ducklake orchestrator
The only orchestrator with zero-config DuckDB, Ducklake and S3 support. Credentials and connections are handled automatically, just write your query.
DuckDB
Query S3 files with SQL. DuckDB scripts auto-connect to your workspace storage. No credentials to manage, no connection strings to configure.
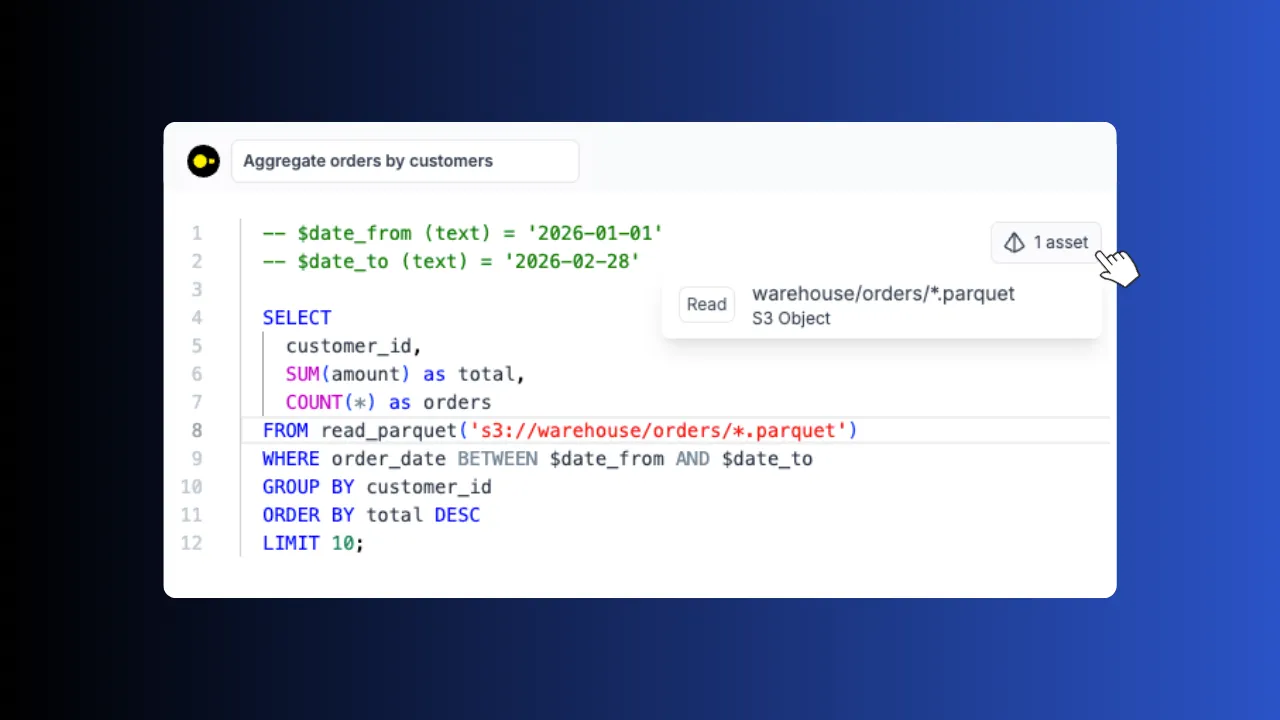
Ducklake
Store massive datasets in S3 and query them with SQL. Full data lake with catalog support, versioning and ACID transactions.
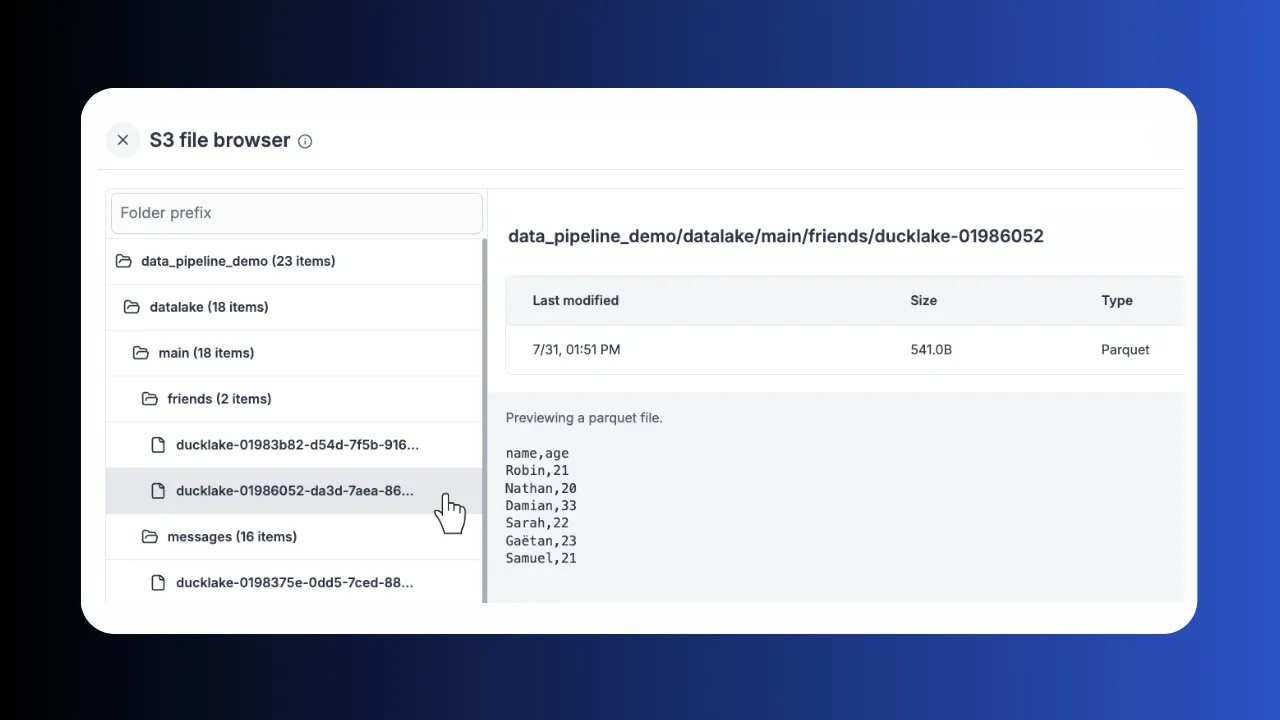
Workspace S3
Link your workspace to S3, Azure Blob, GCS, R2 or MinIO. Browse and preview Parquet, CSV and JSON directly from the UI.
Polars
Lightning-fast DataFrames in Python. Read and write Parquet directly from your workspace S3 bucket with zero config.
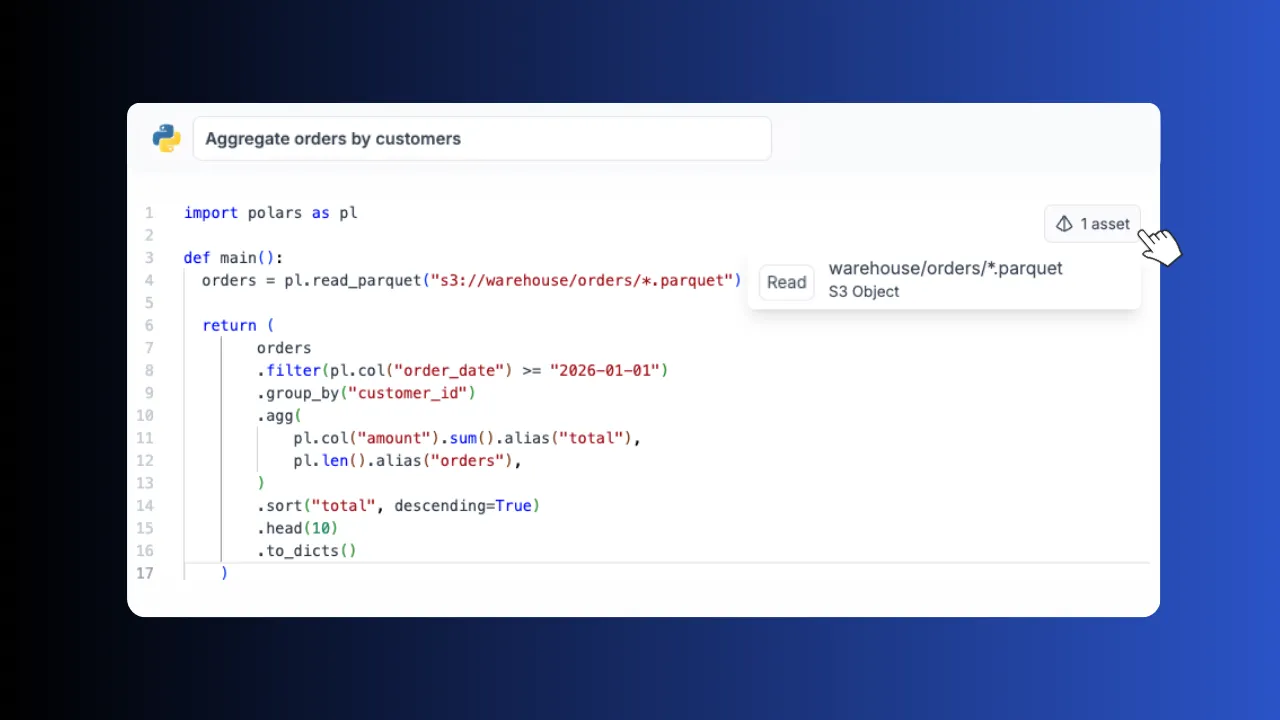
Assets lineage
Pipeline steps pass datasets as lightweight JSON pointers to S3 objects. No serialization overhead, no memory limits.
Challenging the status quo of data warehouses
Stop paying per-query. Run DuckDB and Ducklake locally on your workers.
| Windmill + DuckDB | Snowflake / BigQuery | |
|---|---|---|
| Compute | Local on your workers | Remote warehouse |
| Cost model | Flat, pay for infra only | Per-query pricing |
| Data storage | Your S3 bucket, open formats | Vendor-managed, proprietary |
| Vendor lock-in | No | Yes |
| Orchestration | Built-in (flows, retries, schedules) | Separate tool needed |
| Setup | Zero config, auto-connected | Credentials, drivers, networking |
| Data egress fees | No | Yes |
Windmill also orchestrates Snowflake, BigQuery and other warehouses. You can mix local DuckDB steps with remote warehouse queries in the same pipeline.
Production-grade performance that replaces Spark
Polars and DuckDB process data on a single node far faster than distributed frameworks for the vast majority of ETL workloads.
TPC-H benchmark, 8 queries on m4.xlarge (8 vCPUs, 32 GB RAM)
More you can build on Windmill
Data pipelines are just one use case. The same platform powers internal tools, AI agents, workflows and triggers.
Build production-grade internal tools with backend scripts, data tables and React, Vue or Svelte frontends.

Build AI agents with tool-calling, DAG orchestration, sandboxes and direct access to your scripts and resources.
Chain scripts into flows with approval steps, parallel branches, loops and conditional logic.
Run cron jobs with a visual builder, execution history, error handlers, recovery handlers and alerting.
Frequently asked questions
Build your internal platform on Windmill
Scripts, flows, apps, and infrastructure in one place.